Checkpoint
A Checkpoint is the primary means for validating data in a production deployment of Great Expectations.
Checkpoints provide a convenient abstraction for bundling the ValidationThe act of applying an Expectation Suite to a Batch. of a Batch (or Batches)A selection of records from a Data Asset. of data against an Expectation SuiteA collection of verifiable assertions about data. (or several), as well as the ActionsA Python class with a run method that takes a Validation Result and does something with it that should be taken after the validation.
Like Expectation Suites and Validation ResultsGenerated when data is Validated against an Expectation or Expectation Suite., Checkpoints are managed using a Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components., and have their own Store which is used to persist their configurations to YAML files. These configurations can be committed to version control and shared with your team.
Relationships to other objects
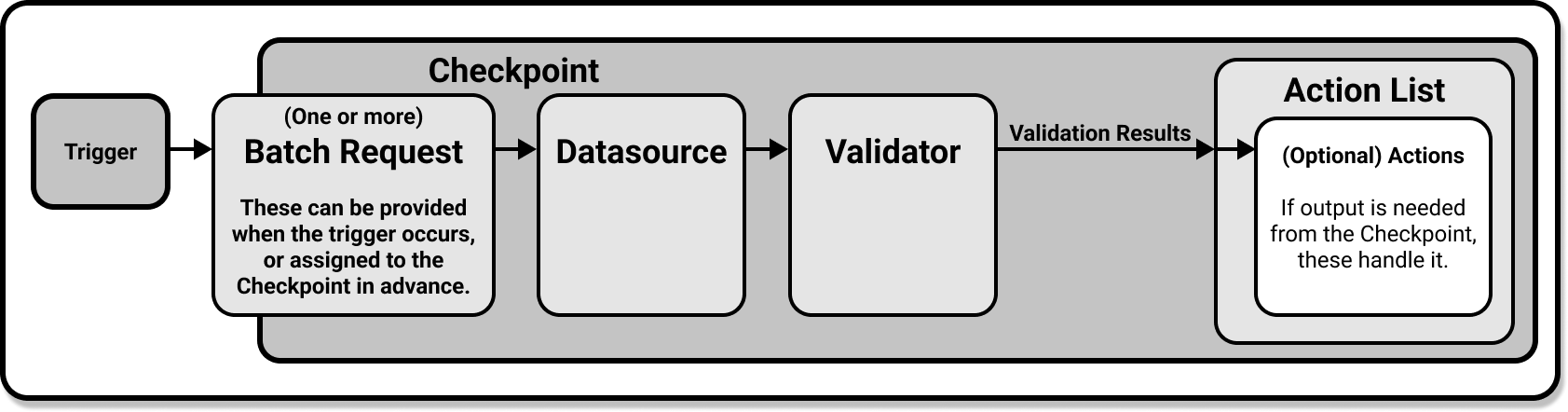
A Checkpoint uses a ValidatorUsed to run an Expectation Suite against data. to run one or more Expectation Suites against one or more Batches provided by one or more Batch RequestsProvided to a Data Source in order to create a Batch.. Running a Checkpoint produces Validation Results and will result in optional Actions being performed if they are configured to do so.
Use cases
In the Validate Data step of working with Great Expectations, there are two points in which you will interact with Checkpoints in different ways: First, when you create them. And secondly, when you use them to actually Validate your data.
Reusable
You do not need to re-create a Checkpoint every time you Validate data. If you have created a Checkpoint that covers your data Validation needs, you can save and re-use it for your future Validation needs. Since you can set Checkpoints up to receive some of their required information (like Batch Requests) at run time, it is easy to create Checkpoints that can be readily applied to multiple disparate sources of data.
Actions
One of the most powerful features of Checkpoints is that they can be configured to run Actions, which will do some process based on the Validation Results generated when a Checkpoint is run. Typical uses include sending email, slack, or custom notifications. Another common use case is updating Data Docs sites. However, Actions can be created to do anything you are capable of programing in Python. This gives you an incredibly versatile tool for integrating Checkpoints in your pipeline's workflow!
To set up common Action use cases, see Configure Actions.
The classes that implement Checkpoints are in the great_expectations.checkpoint module.
Create
Creating a Checkpoint is part of the initial setup for data validation. Checkpoints are reusable and only need to be created once, although you can create multiple Checkpoints to cover multiple Validation use cases. For more information about creating Checkpoints, see How to create a new Checkpoint.
After you create a Checkpoint, you can use it to Validate data by running it against a Batch or Batches of data. The Batch Requests used by a Checkpoint during this process may be pre-defined and saved as part of the Checkpoint's configuration, or the Checkpoint can be configured to accept one or more Batch Request at run time. For more information about data validation, see How to validate data by running a Checkpoint.
In its most basic form, a Checkpoint accepts an expectation_suite_name identfying the test suite to run, and a batch_request identifying the data to test. Checkpoint can be directly directly in Python as follows:
checkpoint = context.add_or_update_checkpoint(
name="my_checkpoint",
validations=[
{
"batch_request": batch_request,
"expectation_suite_name": "my_expectation_suite",
},
],
)
For an in-depth guide on Checkpoint creation, see our guide on how to create a new Checkpoint.
Configure
A Checkpoint uses its configuration to determine what data to Validate against which Expectation Suite(s), and what actions to perform on the Validation Results - these validations and Actions are executed by calling a Checkpoint's run method (analogous to calling validate with a single Batch). Checkpoint configurations are very flexible. At one end of the spectrum, you can specify a complete configuration in a Checkpoint's YAML file, and simply call my_checkpoint.run(). At the other end, you can specify a minimal configuration in the YAML file and provide missing keys as kwargs when calling run.
At runtime, a Checkpoint configuration has three required and three optional keys, and is built using a combination of the YAML configuration and any kwargs passed in at runtime:
Required keys
-
name: user-selected Checkpoint name (e.g. "staging_tables") -
config_version: version number of the Checkpoint configuration -
validations: a list of dictionaries that describe each validation that is to be executed, including any actions. Each validation dictionary has three required and three optional keys:Required keys
batch_request: a dictionary describing the batch of data to validate (learn more about specifying Batches here: Batches)expectation_suite_name: the name of the Expectation Suite to validate the batch of data againstaction_list: a list of actions to perform after each batch is validated
Optional keys
name: providing a name will allow referencing the validation inside the run by name (e.g. " user_table_validation")evaluation_parameters: used to define named parameters using Great Expectations Evaluation Parameter syntaxruntime_configuration: provided to the Validator'sruntime_configuration(e.g.result_format)
Optional keys
class_name: the class of the Checkpoint to be instantiated, defaults toCheckpointtemplate_name: the name of another Checkpoint to use as a base templaterun_name_template: a template to create run names, using environment variables and datetime-template syntax (e.g. "%Y-%M-staging-$MY_ENV_VAR")
Configure defaults and parameter override behavior
Checkpoint configurations follow a nested pattern, where more general keys provide defaults for more specific ones. For instance, any required validation dictionary keys (e.g. expectation_suite_name) can be specified at the top-level (i.e. at the same level as the validations list), serving as runtime defaults. Starting at the earliest reference template, if a configuration key is re-specified, its value can be appended, updated, replaced, or cause an error when redefined.
Replaced
namemodule_nameclass_namerun_name_templateexpectation_suite_name
Updated
batch_request: at runtime, if a key is re-defined, an error will be thrownaction_list: actions that share the same user-defined name will be updated, otherwise a new action will be appendedevaluation_parametersruntime_configuration
Appended
action_list: actions that share the same user-defined name will be updated, otherwise a new action will be appendedvalidations
Checkpoint configuration default and override behavior
- No nesting
- Nesting with defaults
- Keys passed at runtime
- Using template
This configuration specifies full validation dictionaries - no nesting (defaults) are used. When run, this Checkpoint will perform one validation of a single batch of data, against a single Expectation Suite ("my_expectation_suite").
YAML:
context.add_or_update_checkpoint(
name="my_checkpoint",
run_name_template="%Y-%M-foo-bar-template-$VAR",
validations=[
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "01"},
},
"expectation_suite_name": "my_expectation_suite",
"action_list": [
{
"name": "<action>",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "<action>",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "<action>",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
}
],
evaluation_parameters={"GT_PARAM": 1000, "LT_PARAM": 50000},
runtime_configuration={
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
)
runtime:
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
This configuration specifies four top-level keys ("expectation_suite_name", "action_list", "evaluation_parameters", and "runtime_configuration") that can serve as defaults for each validation, allowing the keys to be omitted from the validation dictionaries. When run, this Checkpoint will perform two Validations of two different Batches of data, both against the same Expectation Suite ("my_expectation_suite"). Each Validation will trigger the same set of Actions and use the same Evaluation ParametersA dynamic value used during Validation of an Expectation which is populated by evaluating simple expressions or by referencing previously generated metrics. and runtime configuration.
YAML:
context.add_or_update_checkpoint(
name="my_checkpoint",
run_name_template="%Y-%M-foo-bar-template-$VAR",
validations=[
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "01"},
},
},
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "02"},
},
},
],
expectation_suite_name="my_expectation_suite",
action_list=[
{
"name": "<action>",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "<action>",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "<action>",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
evaluation_parameters={"GT_PARAM": 1000, "LT_PARAM": 50000},
runtime_configuration={
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
)
Runtime:
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
Results:
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
first_batch_identifiers = first_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
second_batch_identifiers = second_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "taxi_asset"
assert first_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-01.csv",
"year": "2019",
"month": "01",
}
assert second_expectation_suite == "my_expectation_suite"
assert second_data_asset == "taxi_asset"
assert second_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-02.csv",
"year": "2019",
"month": "02",
}
This configuration omits the "validations" key from the YAML, which means a "validations " list must be provided when the Checkpoint is run. Because "action_list", "evaluation_parameters", and "runtime_configuration" appear as top-level keys in the YAML configuration, these keys may be omitted from the validation dictionaries, unless a non-default value is desired. When run, this Checkpoint will perform two validations of two different batches of data, with each batch of data validated against a different Expectation Suite ("my_expectation_suite" and "my_other_expectation_suite", respectively). Each Validation will trigger the same set of actions and use the same Evaluation ParametersA dynamic value used during Validation of an Expectation which is populated by evaluating simple expressions or by referencing previously generated metrics. and runtime configuration.
YAML:
context.add_or_update_checkpoint(
name="my_base_checkpoint",
run_name_template="%Y-%M-foo-bar-template-$VAR",
action_list=[
{
"name": "<action>",
"action": {"class_name": "StoreValidationResultAction"},
},
{
"name": "<action>",
"action": {"class_name": "StoreEvaluationParametersAction"},
},
{
"name": "<action>",
"action": {"class_name": "UpdateDataDocsAction"},
},
],
evaluation_parameters={"GT_PARAM": 1000, "LT_PARAM": 50000},
runtime_configuration={
"result_format": {"result_format": "BASIC", "partial_unexpected_count": 20}
},
)
Runtime:
results = context.run_checkpoint(
checkpoint_name="my_base_checkpoint",
validations=[
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "01"},
},
"expectation_suite_name": "my_expectation_suite",
},
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "02"},
},
"expectation_suite_name": "my_other_expectation_suite",
},
],
)
Results:
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
first_batch_identifiers = first_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_batch_identifiers = second_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "taxi_asset"
assert first_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-01.csv",
"year": "2019",
"month": "01",
}
assert second_expectation_suite == "my_other_expectation_suite"
assert second_data_asset == "taxi_asset"
assert second_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-02.csv",
"year": "2019",
"month": "02",
}
This configuration references the Checkpoint detailed in the previous example ("Keys passed at runtime"), allowing the runtime call to be much slimmer.
YAML:
context.add_or_update_checkpoint(
name="my_checkpoint",
template_name="my_base_checkpoint",
validations=[
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "01"},
},
"expectation_suite_name": "my_expectation_suite",
},
{
"batch_request": {
"datasource_name": "taxi_datasource",
"data_asset_name": "taxi_asset",
"options": {"year": "2019", "month": "02"},
},
"expectation_suite_name": "my_other_expectation_suite",
},
],
)
Runtime:
results = context.run_checkpoint(checkpoint_name="my_checkpoint")
Results:
first_validation_result = list(results.run_results.items())[0][1]["validation_result"]
second_validation_result = list(results.run_results.items())[1][1]["validation_result"]
first_expectation_suite = first_validation_result["meta"]["expectation_suite_name"]
first_data_asset = first_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
first_batch_identifiers = first_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
second_expectation_suite = second_validation_result["meta"]["expectation_suite_name"]
second_data_asset = second_validation_result["meta"]["active_batch_definition"][
"data_asset_name"
]
second_batch_identifiers = second_validation_result["meta"]["active_batch_definition"][
"batch_identifiers"
]
assert first_expectation_suite == "my_expectation_suite"
assert first_data_asset == "taxi_asset"
assert first_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-01.csv",
"year": "2019",
"month": "01",
}
assert second_expectation_suite == "my_other_expectation_suite"
assert second_data_asset == "taxi_asset"
assert second_batch_identifiers == {
"path": "yellow_tripdata_sample_2019-02.csv",
"year": "2019",
"month": "02",
}
CheckpointResult
The return object of a Checkpoint run is a CheckpointResult object. The run_results attribute forms the backbone of this type and defines the basic contract for what a Checkpoint's run method returns. It is a dictionary where the top-level keys are the ValidationResultIdentifiers of the Validation Results generated in the run. Each value is a dictionary having at minimum, a validation_result key containing an ExpectationSuiteValidationResult and an actions_results key containing a dictionary where the top-level keys are names of Actions performed after that particular Validation, with values containing any relevant outputs of that action (at minimum and in many cases, this would just be a dictionary with the Action's class_name).
The run_results dictionary can contain other keys that are relevant for a specific Checkpoint implementation. For example, the run_results dictionary from a WarningAndFailureExpectationSuiteCheckpoint might have an extra key named "expectation_suite_severity_level" to indicate if the suite is at either a "warning" or "failure" level.
CheckpointResult objects include many convenience methods (e.g. list_data_asset_names) that make working with Checkpoint results easier. You can learn more about these methods in the documentation for class: great_expectations.checkpoint.types.checkpoint_result.CheckpointResult.
Below is an example of a CheckpointResult object which itself contains ValidationResult, ExpectationSuiteValidationResult, and CheckpointConfig objects.
Example CheckpointResult
results = {
"run_id": RunIdentifier,
"run_results": {
ValidationResultIdentifier: {
"validation_result": ExpectationSuiteValidationResult,
"actions_results": {
"<action>": {
"class": "StoreValidationResultAction"
}
},
}
},
"checkpoint_config": CheckpointConfig,
"success": True,
}
Example script
To view the full script used in this page, see checkpoints_and_actions.py